
CVAD
[논문리뷰] U-Net : Convolutional Networks for Biomedical Image Segmentation 본문
[논문리뷰] U-Net : Convolutional Networks for Biomedical Image Segmentation
_DK_Kim 2023. 12. 18. 14:24논문 원본 링크 : https://arxiv.org/abs/1505.04597
이제 졸업 논문도 끝났고, 지금까지 읽었던 논문과 연구실에서 진행했던 토이 프로젝트를 본격적으로 정리해나가려고
한다! (아마, 논문은 이전에 비공개로 썼던 것들도 수정해서 올릴거라 순서가 뒤죽박죽일 것 같다...)
1. 논문 간략 소개
- 저자 :
Olaf Ronnenberger, Philipp Fischer and Thomas Brox - 게재 정보 :
Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer International Publishing, 2015. - Main Contribution :
- U-Net architecture : local과 contextual information을 잘 학습할 수 있는 모델을 제안
- Data augmentation : 적은 데이터만 사용하여도 제안된 증강 기법을 통해 충분한 데이터셋을 확보할 수 있다.
- Loss function : 객체 간의 경계를 더욱 분명하게 해주는 손실 함수를 정의
2. Introduction
논문은 기존의 CNN 모델들은 Computer vision 문제를 다루는데 유용하지만, 몇 가지 문제점이 존재한다는 것을 언급하며 시작한다. 특히 저자는, 의학 분야에서 기존의 모델들의 적용이 어렵다는 것을 강조한다.


(1) 사용가능한 training set의 크기
기존의 CNN 기반의 모델들은 많은 학습 데이터 셋을 필요로 하며, 계산상의 제한으로 인해 모델의 크기에 다소 제약이
있었다. 이에 대해 AlexNet 으로 알려진 Krizhevsky의 모델은 ImageNet이라는 대규모 데이터 셋에서 우수한 성능을
보여주었다. 하지만, 의학 분야에서는 ImageNet과 같은 대규모 데이터셋을 준비하는 것이 어렵다.
(2) Task의 문제
기존의 모델들은 Image classification을 목적으로 제안되어왔지만, 몇몇 분야의 경우 픽셀 단위로 라벨링
(segmentation)이 필요한 경우가 있다(특히, 의학분야). 때문에, 이러한 필요성을 충족할 모델의 연구가 필요하다.
2.1 기존의 해결방식

물론, 이러한 문제를 해결하고자 연구가 진행되고 있다. 저자는 그 중 VGGNet 으로 잘 알려진 Ciresan의 논문을 언급하며 아래와 같이 소개한다.
- Ciresan et al.(2012) : 전자 현미경 스택에서 segmentation을 위한 sliding window convoltuion network 구조를 제안
- 특징 :
각 픽셀 주변의 영역을 patch로 잘라 픽셀당 클래스 라벨을 예측하는 방식으로 모델을 훈련. 이러한 방법으로
제안된 모델이 localization을 수행할 수 있었고, 적은 이미지로도 많은 양의 훈련 데이터셋을 확보할 수 있었다. - 단점 :
patch간 겹치는 영역으로 인해 시간적으로 학습이 비효율적이었으며, localization과 context 정보의 활용 사이에 trade-off가 존재한다.
- 특징 :
VGGNet의 trade-off
이미지의 Context 정보를 최대한 유지하려면, 큰 사이즈의 patch를 사용해야함. 반면, localization의 정확성을
높이기 위해선 작은 patch를 사용해야함.
이때, 큰 patch를 사용하면 모델 architecture를 맞추기 위해 더 많은 Max pooling layer가 필요하며 이에 따라 데이터
정보의 소실이 발생할 가능성이 높아진다. (즉, 세부적인 정보(local한 정보)의 소실이 발생할 수도 있다)
즉, 위의 내용을 정리하면 아래와 같은 trade-off가 발생한다.

2.2 논문에서 제안하는 모델
저자들은 U-Net이라는 모델을 제안하여 적은 학습 이미지로도 local 과 contextual information을 잘 학습할 수 있다고
얘기하며, 적은 데이터로도 논문에서 제안된 data augmentation을 통해 많은 학습 데이터를 확보할 수 있다고 한다.
또한, 제안된 손실 함수는 모델이 객체 간의 경계를 더 분명하게 학습 할수 있도록 한다고 한다.
U-Net 모델은 Fully convolutional Network 모델을 응용하여 만들어졌으며, 그 차이는 다음과 같다.

(1) Up-sampling 에서 channel의 수를 크게 가짐 :
Contracting path와 동일하게 많은 channel의 feature map을 사용함으로써, 네트워크가 입력 이미지로부터 더 많은
정보를 포착하고 segmentation 성능을 높일 수 있도록 함. 그 결과, 대칭적인 구조를 형성하여 모델의 이름처럼
U 형태의 모양을 띄게 된다.
(2) Fully connected layer를 사용하지 않고 convolution layer을 사용 :
- only uses the valid part of each convolution :
가장자리의 픽셀들은 사용하지 않음. 즉, padding을 사용하지 않음
- segmentation ~ full context is available :
contextual information이 존재하는 픽셀에 대해서만 입력으로 사용함으로써 segmentation을 적용
Overlap-tile 전략을 통해 (2)에서 처리하지 않은 픽셀들의 정보를 보완
2.2 Overlap-tile strartegy
저자들은 이미지를 patch로 분할 할때, overlap-tile 이라는 기법을 사용하였다. 과연 이 기법은 무엇일까?
그걸 알아보기 전에 먼저, 기존의 patch를 분할하는 방식을 알아보자
- 기존의 patch 분할

위의 그림에서 알 수 있듯이, 기존의 patch 분할 방식은 patch마다 겹치는 부분이 존재하여 이 겹치는 부분으로 인해 모델의 학습속도가 느려진다고 주장한다.
- Overlap-tile 방식

Overlap-tile 방식은 원본 이미지에서 잘라낸 patch를 바로 사용하지 않고, 위의 그림처럼 Missing context라고 적힌 공간을 채워 넣기 위해 반전(mirroring) 하여 빈 부분을 채워 넣는다.
여기서 모델은 반전된 이미지로 채워진 input tile을 입력으로 사용하는데, 실제 예측하는 부분은 빨간색 박스로 둘러쌓인 원본 이미지의 patch 부분이다. 이를 통해 입력 이미지의 크기와 출력된 결과의 크기가 서로 다르다는 것을 알 수 있다.
모든 patch에 대해서 overlap-tile이 사용되는 걸까?
한동안 U-Net을 볼 때 이런 생각이 들었다. 위의 process를 보면 알겠지만, 원본 이미지에서 1차로 특정 크기의
patch를 잘라내고, 그 패치에 대해 input tile을 생성한다. 근데 잘라내 patch가 이미지의 중심 부에 위치해서
처음부터 input tile을 만들 수 있는 경우라면 overlap-tile을 적용할까? 라는 생각이 들었다.
근데 다시 생각해보면 패치 간 중복을 없애려고 위 전략을 사용한건데, 이럴 경우는 겹치는 부분이 발생한다.
즉, 결론적으로 전체 patch에 대해 미러링을 한다는 것이다.
왜 안겹치게 잘라낸 patch를 사용하지 않고 굳이 미러링을 통해 이미지를 키울까?
입력 이미지는 모델을 통해 전달되는 동안 계속 수축하게 된다. (패딩이 없으므로) 이 과정에서 각 패치의 테두리에
위치한 값들은 점점 사라지거나 소실되는데, 다르게 말하면 해당 부분들의 contextual information이 소실되는 것이다.
이를 막기 위해 내부의 이미지를 복사해서 테두리에 패딩하듯이 둘러주는 게 아닐까 생각이든다.
이러한 전략은 특히 세포 이미지에서 유효하다고 생각드는데, 세포들 이미지는 대칭적인 경우가 많아서 그런 것 같다.
이런 전략이 비대칭성이 강한 이미지에서 유효할까? 라는 궁금증도 생긴다.
저자들은 무엇보다도 이러한 방법이 큰 이미지를 patch로 분할하여 입력함으로써, GPU 메모리 제한으로 인한 해상도
저하를 피할 수 있다고 주장한다.
(고해상도의 이미지라도 patch 단위로 쪼개서 넣으면 입력 가능하고 쪼갤 때 발생하는 문제는 overlap-tile로 커버
가능하니까 이러한 방법이 유효하다는 말인것 같다.)
3. Network Architecture
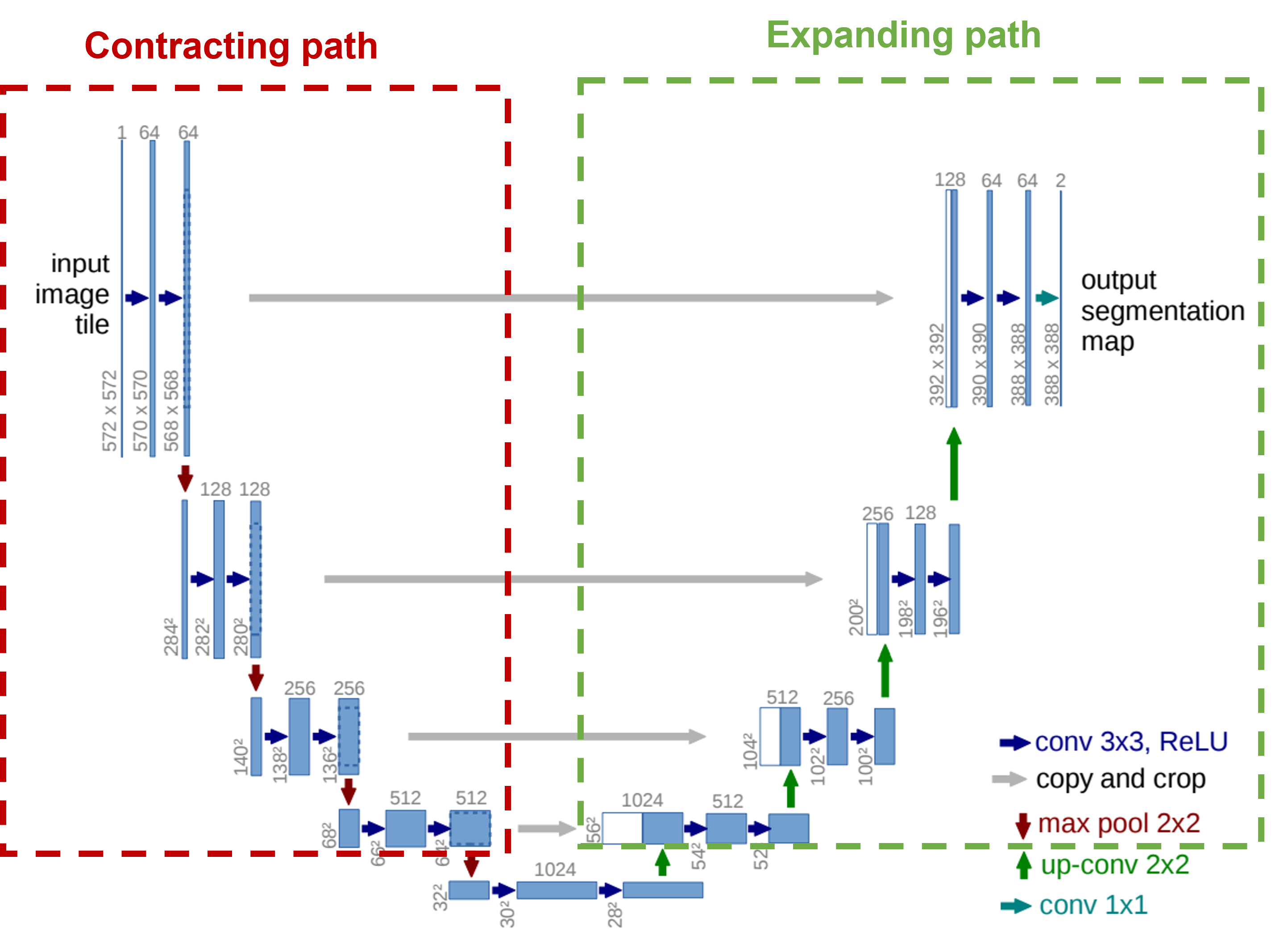
이제 모델의 구조를 살펴보자. 앞서 언급한 것처럼 input image의 크기와 output segmentation map의 크기를 비교해보면 output이 더 작은 것을 볼 수 있다.(572 × 572 크기가 overlap-tile이 적용된 크기이고, 388 × 388이 원본 이미지의 패치라는 걸 알 수 있을 것이다. ) U-Net의 구조는 크게 2가지 단계로 나눌 수 있다.
사실, 저 2 구간에 속하지 않은 중간 부분을 bottle neck이라고 부르곤 하는데, 두 구간에 속하진 않고 논문에서도 별도의 언급이 없는 것 같아서 따로 특정 부분에 넣진 않았다.
(1) Contracting path :
위 그림에서 알 수 있듯이, 총 4번의 down-sampling이 발생한다. 한 번의 down-sampling이 발생하기까지의 과정은
다음과 같다.
3×3 convolution layer → ReLU → 3×3 convolution layer → ReLU → 2×2 max pooling
이때, convolution layer는 padding을 해주지 않고, down-sampling된 feature map의 채널을 2배로 해준다.
그리고 각 이때 얻은 feature map은 expanding path에 사용할 수 있도록 복사해준다.(Skip-connection)
(2) Expanding path :
마찬가지로, 총 4번의 up-sampling이 발생하며, 각 up-sampling 마다 feature map의 채널 수는 절반으로 줄어든다.
한 번의 up-sampling의 처리 과정은 아래와 같다.
2×2 convolution layer → Concat with feature map → ( 3×3 convolution layer → ReLU ) × 2
먼저, 2×2 convolution layer를 통해 feature map의 채널을 절반으로 줄이고, 해상도를 높인다.
그 후 Contract path에서 skip-connection을 통해 전달받을 feature map을 concat한다. 이 값을 다시3×3 convolution
layer와 ReLU에 입력해준다.
최종적으로는 1×1 convolution layer 를 통해 segmentation map을 반환한다.
여기서 map의 채널이 2인 이유는 최종 결과가 0과 1을 통해 세포인지 아닌지만 구분해서 그렇다.
그림만 봐도 알겠지만, Encoder-Decoder 구조다. Contracting path가 encoder에 해당하는 부분이고, Expanding path가 decoder에 해당하다. 구조도 아주 명확하고 간단하다.
4. Training
저자들의 학습 세부 설정과 main contribution에서 언급했던 loss function을 다루고 있는 부분이다. 사실 이 챕터의 가장 핵심은 loss function이기 때문에, 학습 세부 설정을 빠르게 요약하면 아래와 같다.
- Optimizer : SGD
- Momentum 0.99
- Overhead와 GPU memory의 사용을 극대화시키기 위해 큰 batch size보다 큰 input tiles 사용
- Deep learning frame work : Caffe
논문에서 제안된 loss function은 Energy function으로 지칭하며, pixel-wise soft max의 결과에 대해 cross entropy를 계산한뒤 자체적으로 정의한 weight function을 사용하여 가중치를 곱해줌으로써 계산된다.
4.1 Energy function
Energy function ( E ) =$$\sum_{\text{x} \in \Omega} w(\text{x})\log{p_{l(\text{x})}(\text{x})}$$
위 식에서 log 부분은 $\text{x}$는 픽셀의 위치를 나타내며 $\Omega$는 input tile 전체의 픽셀의 위치를 나타낸다.
사실 cross entropy를 손실함수로 정의하여 학습을 하는 것은 일반적인 방식 중 하나이므로, 내가 생각하는 이 논문의
차별점은 저자들이 정의한 weight function($w(\text{x}$))에 있다고 생각한다.
이에 대해 알아보기 앞서, 왜 저자들은 weight function을 사용할 생각을 했을까? 답은 아래와 같다.


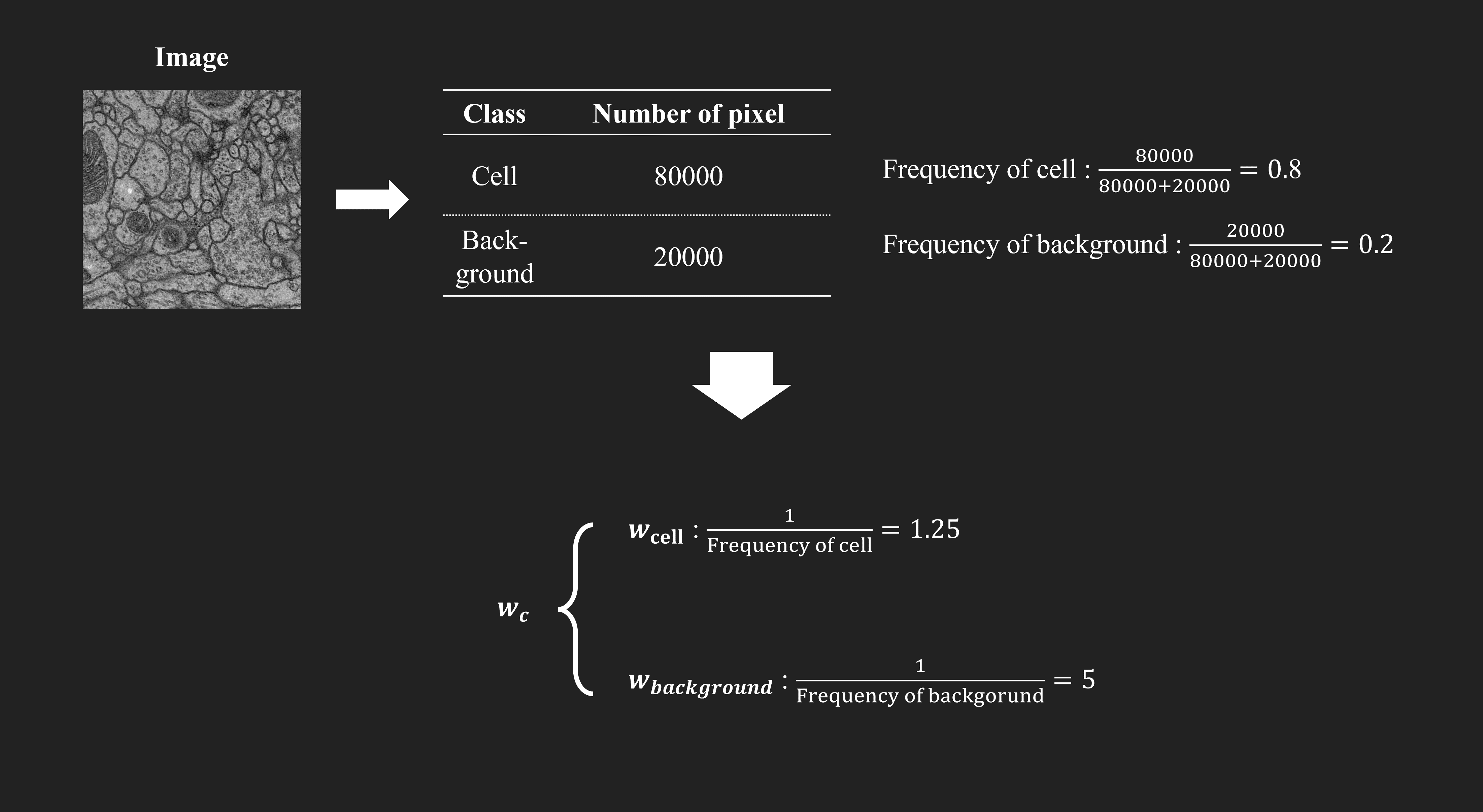
class 마다의 서로 다른 빈도 수에 대해 보상하고 붙어있는 세포간의 경계선을 잘 학습시키기 위한 것이다.
아마 데이터셋에서 세포로 정의된 pixel과 아닌 pixel의 수가 크게 차이가 나기 때문에 class imbalance를 해결할 필요가
있었고, Fig.3 의 그림 (b), (c)에서 볼 수 있듯이 서로 붙어있는 세포들 사이에도 세포벽이 존재하여 이 부분을 더 잘
포착하기 위한 방법이 필요했을 것이다. 저자들은 이러한 문제를 weight function으로 해결하였다고 주장한다.
여기서 weight function에 대한 정의는 아래와 같다.
$$w(x) = w_c(\text{x}) + w_0 \cdot \exp\left(-\frac{(d_1( \text{x} ) + d_2( \text{x} ))^2}{2\sigma^2}\right)$$
위의 수식에서 $w_c(\text{x})$가 바로 class 별 픽셀 수의 차이를 보상하기 위한 값이고, 뒤의 값들은 붙어있는 세포들
사이의 경계(아마 세포벽)를 잘 포착하기 위한 부분이다. 각 값을 계산하는 설명은 아래의 그림을 참고하면 된다.

4.2 Data augmentation
논문에서 언급된 augmentation 방법은 총 4가지다. Shift, Rotate, Gray value, Random elastic deformations
이 중 Gray value와 Random elastic deformation은 다소 생소할 수 있어서 따로 정리해보자면 다음과 같다.
- Gray value :
Gray value 자체는 픽셀의 밝기값을 나타낸다. (intensity value 라고도 함). 이미지의 밝기 값을 조절하여 원본이미지와 비슷하지만 다른 이미지를 생성하는 data augmentation 기법을 말한다.
- Random elastic deformation :

이미지에 왜곡을 주어 이미지에 부드러운 변형을 주는 방법. 위의 그림에서 나와있듯이, 특정 그리드 기준으로
gaussian 분포를 따르는 변위 벡터(파란 화살표)를 추출하여 왜곡시킨 뒤 보간을 통해 이미지에 왜곡을 줌.
(굳이 가우시안을 따르게한건 아마 전체적인 이미지 변형 관점에서 합이 0이 되도록 하기위해서인 것 같다... )
5. Experiments
저자들은 U-Net의 유효성을 검증하기 위해 3개의 segmentation을 진행하였다.
- Neuronal structures in electron microscopic recording :
ISBI 2012의 dataset을 학습시켜서 EM segmentation challenge에서 가장 좋은 wraping error를 얻음. - Cell segmentation task :
ISBI Cell Tracking challenge 2014, 2015에서 PhC-U373 dataset에서 가장 좋은 성능을 보임 - DLC-HeLa dataset :
2등 모델(IoU : 46%)보다 훨씬 높은 77.5%의 IoU를 보여줌.
이를 통해 U-Net 모델과 data augmentation 방식들이 상당히 유효했다고 말한다.
6. Conclusion
일단 U-Net 논문은 현재를 기준으로는 정말 오래된 논문이다. 하지만, 발표 당시 기존의 모델들에 비해 훨씬 좋은 성능을
보여주었고 특히, data augmentation 방법에 대한 접근은 지금 생각해도 정말 좋은 방법인 것 같다. 데이터셋이 세포이기 때문에 미러링과 Random elastic deformation이 더 큰 효과를 발휘할 수 있었던 것 같다.
결국, 좋은 모델도 중요하지만 유효한 데이터 증강 방식도 성능에 큰 영향을 준다는 것을 명심해야할 것 같다.
'Paper review' 카테고리의 다른 글
| [논문 리뷰] R-CNN : Rich feature hierarchies for accurate object detectction... (0) | 2024.01.24 |
|---|---|
| [논문리뷰] Fully Convolutional Networks for Semantic Segmentation (0) | 2024.01.09 |

