
CVAD
[VOC PASCAL 2012] Semantic segmentation 하기 - 4 본문
이전 포스팅 내용이 궁금하시다면 아래 링크를 참고해주시면 감사하겠습니다!
- Semantic segmentation 하기 - 1
- Semantic segmentation 하기 - 2
- Semantic segmentation 하기 - 3
이번 포스팅은 VOC PASCAL 데이터셋 예제의 마지막 포스팅이다. 지난번 모델 학습의 결과를 분석해보고, 정리해보는 내용을 다루겠다.
1. 모델 별 비교
이전 포스팅에서 언급하였듯, FCN 모델과 U-Net 모델을 비교하였다. 먼저 loss를 분석해보자.
두 모델 모두 이전 포스팅에서 정의한 Combined Loss에서 weight를 0.5로 설정해서 사용하였다.
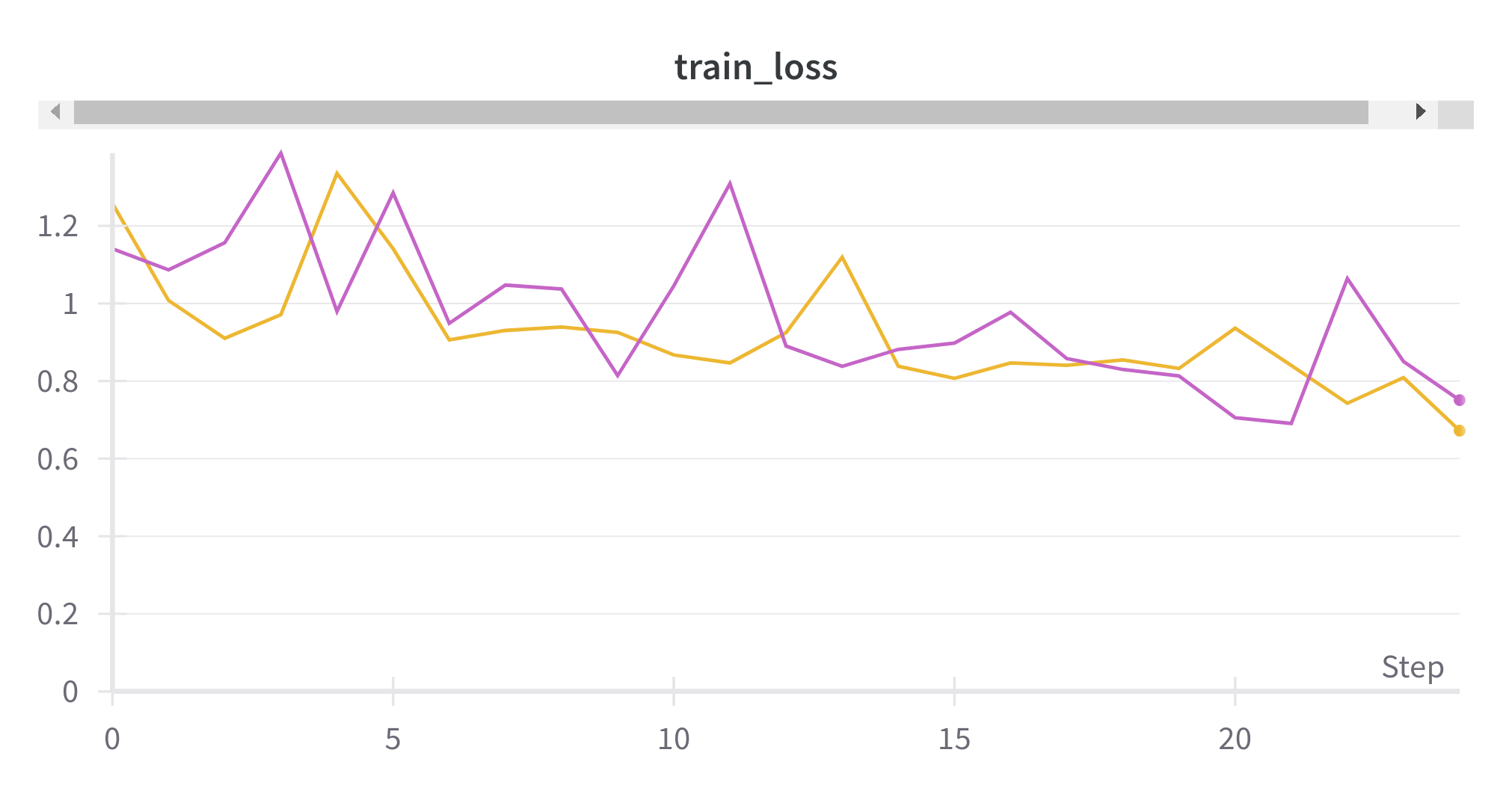
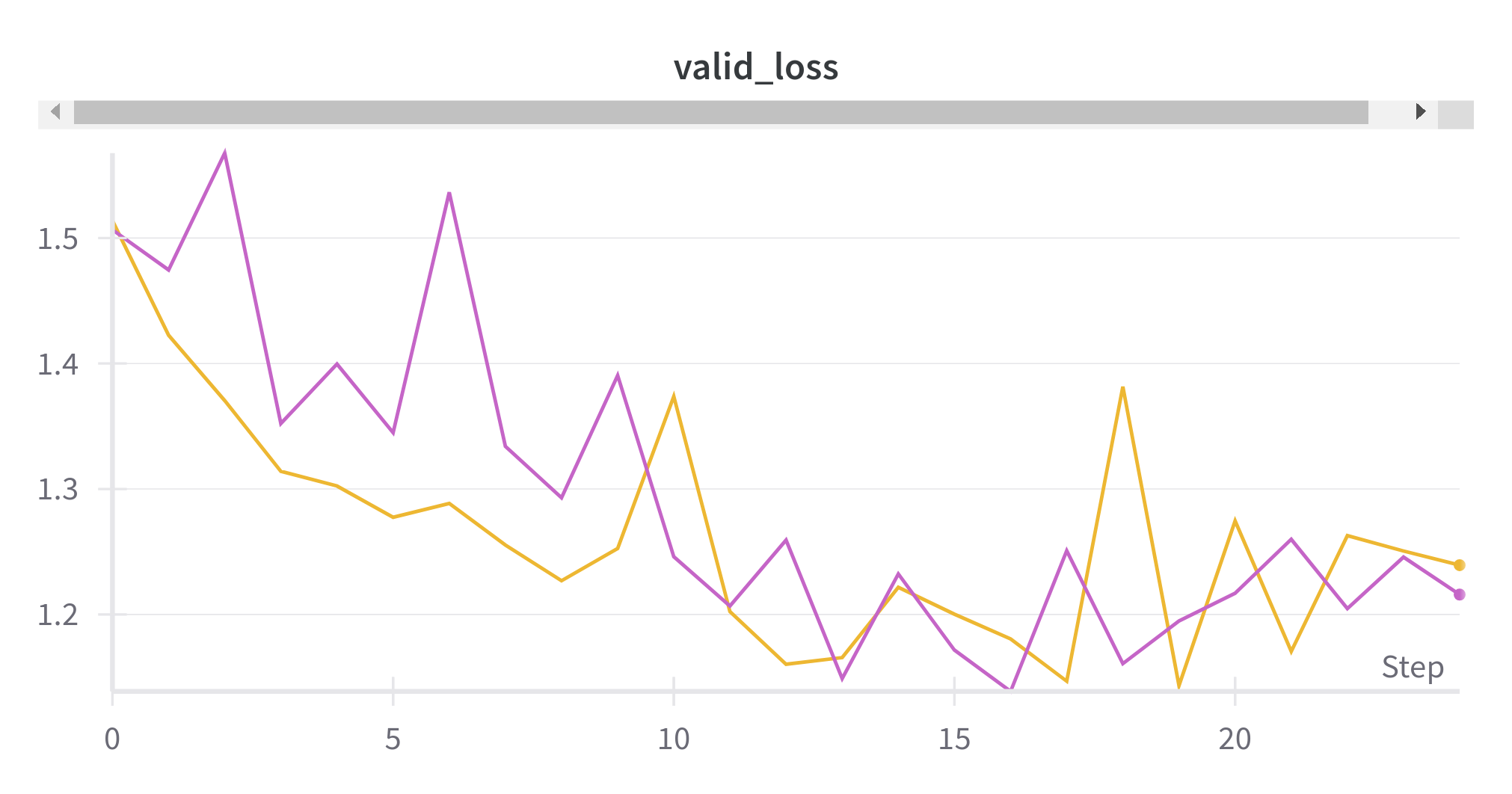
보라색 선이 FCN 모델이고, 노란색 선이 U-Net 모델이다. train과 validation에서 모두 우하향의 경향을 갖고 있다.
학습 전에는 U-Net이 조금 더 좋은 loss를 보여줄 것 같았지만, valid loss의 최솟값은 FCN이 더 낮은 결과를 보여주었다.
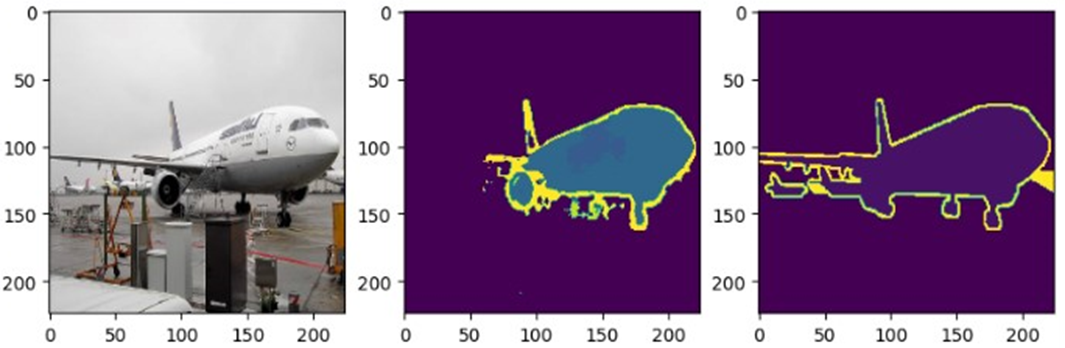
이제 두 모델의 추정 결과를 비교해보자. 먼저 FCN 모델이다.

먼저, 배경과 object를 구분한 것만 본다면, 나쁘지 않게(?) 학습이 된 것 같다. 하지만, 예측 이미지에서 비행기에 해당하는 class 값이 실제 비행기 비행기의 class값과 다르다.
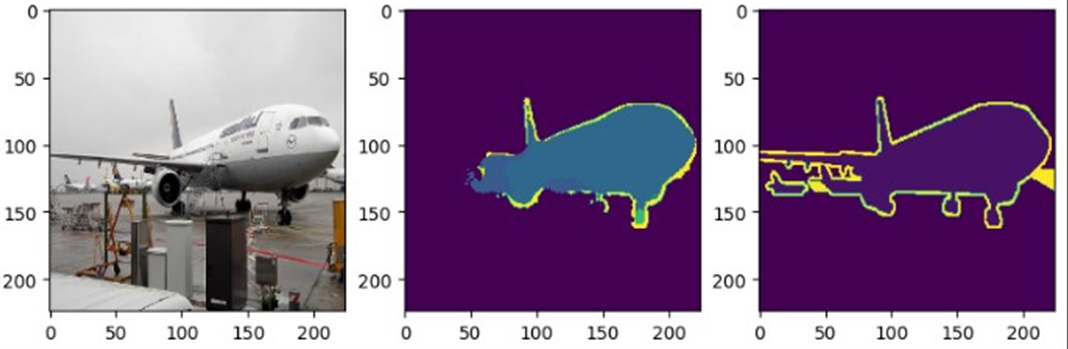
다음은 U-Net의 결과를 보자.
FCN보다 정확하게 비행기와 배경의 경계가 정확한 것을 확인할 수 있었다. 하지만, 이 모델 역시 class값이 정확하지 않을 뿐더러, 엔진 부분과 비행기 몸통 부분 사이에 boundary line이 잡혀있는 것을 볼 수 있다.
이제 class별 mIoU 비교를 통해 정량적으로 비교해보자.

사진이 작아서 잘 안보일 수 있겠지만, 클릭해서 확대해보면 class별 mIoU도 U-Net이 더 좋은 성능을 보이는 것을 확인할 수 있다. 그리고, FCN에서는 인식하지 못한 class도 U-Net에서는 대부분 인식하는 결과도 볼 수 있다.
이러한 결과는 U-Net이 FCN 모델보다 skip connection 수가 많기 때문에 얕은 layer에서의 feature map을 더
많이 반영함으로써, 세부적인 부분을 더 많이 학습할 수 있었기 때문이지 않을까라고 추측된다.
2. Loss combination
이번에는 Loss의 조합에 따른 성능 변화를 살펴보자. 모델은 U-Net을 사용했다.
지난 포스팅에서 언급하였듯, 모델에 학습에는 cross entropy와 dice loss를 결합한 loss를 사용하였다.
아래는 loss의 수식이다.
$$ L = \lambda_{ce} \times L_{ce} + (1 - \lambda_{ce}) \times L_{d} $$
$lambda_ce$의 값을 0.1단위로 0부터 1까지 바꿔가며 결과를 비교해볼 것이다.
먼저, 모델들의 예측 결과부터 살펴보자.
맨 위의 사진은 $ \lambda_{ce}=1 $이고, 아래로 갈수록 0.1씩 감소시켰을 때의 결과다.

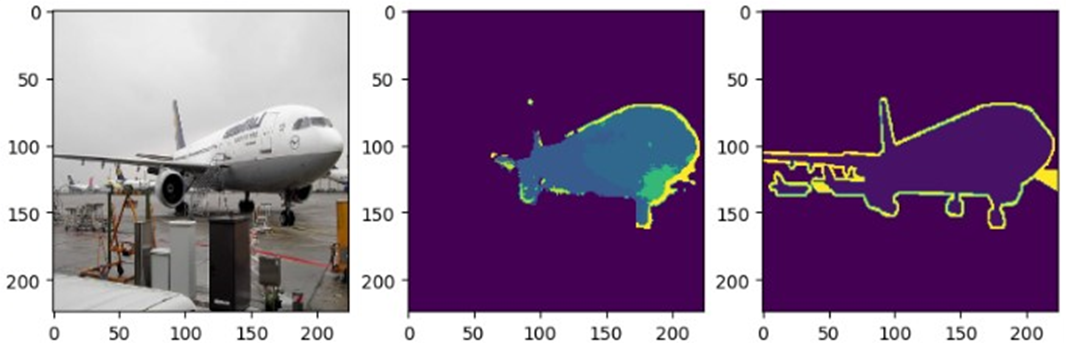
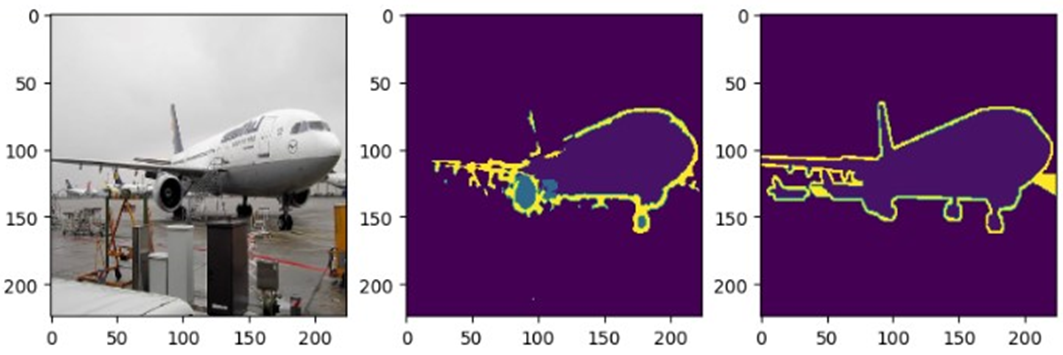







Dice loss의 비율이 증가할 수록, 비행기의 class값을 더 잘 맞춰가는 경향을 보인다. 다만, 비행기외의 object들에 대해서도
인식되는 문제가 발생한다.
class가 더 잘 맞춰지는 현상은 cross entropy와 달리 dice loss가 ground truth와 얼마나 흡사하게 예측하는 가를 class별로 동일한 가중값을 갖고 학습하기 때문인 것 같다.
이제 mIoU를 살펴보자.

여기서 살펴볼 점은 크게 2가지다.
첫 번째는 cross entropy나 dice loss를 단일로 사용하는 경우보다, 두 함수를 혼합해서 사용하는 경우가 더 좋은 결과를
보인다는 것이다. cross entropy와 dice loss를 0.7:0.3 혹은 0.1:0.9 비율로 결합한 경우가 단일 사용 경우보다 더 좋은 성능을 보인다.
두 번째는 dice loss가 segmentation 성능에 더 영향을 미친다는 것이다. 앞서 언급한 것처럼, dice loss는 cross entropy보다 class별 반영도가 일정한 편이다. cross entropy는 class 별 예측값보다, 한 이미지 전체에서의 예측 성능에 중점을 둔다.
때문에, 픽셀 빈도가 높은 class를 정확하게 맞추는 것에 초점을 둔다. 때문에 학습된 모델도 픽셀 빈도가 높은 것을 정확하게 맞추려고 하는 방향으로 학습될 확률이 높다. 실제로 표에서도 빈도가 가장 많았던, 0번(배경) class에 대한 mIoU가
cross entropy의 비중이 높을수록 높은 경향을 볼 수 있다.
반면, dice loss는 각 class에 대해 일치하는 부분(intersection)의 비율에 중점을 둔다.
즉, dice loss 관점에서는 학습 데이터의 총 픽셀 수가 1000개인 class 중 200개를 맞춘 것과 총 100개의 픽셀중 20개를 맞춘 class의 비중이 동일하다.
이러한 특성 덕분에 cross entropy와 달리 전체 class에 대해 균등하게 학습이 이루어지고, 표에서 볼 수 있듯이 dice loss의 비율이 높아질수록 인식하는 class의 수가 점점 더 많아지는 경향을 보인다.
물론, 모든 상황에서 절대적으로 위의 경향성을 띈 것은 아니다. 데이터셋의 성질이나, 모델 구조등에 따라 저러한 결과는 얼마든지 바뀔 수도 있고, 표에서의 결과를 보면 알겠지만 절대적인 경향을 가지는 것이 아니다.
가령, dice loss가 빈도가 적은 class에 대해서 인식할 확률이 높다지만, cross entropy와 dice loss의 비율이 0.8:0.2인 경우에는 오히려 성능이 감소하는 경우도 발생한다. 이러한 부분들은 이론적인 내용과는 조금은 다른 결과를 보여준다.
그리고, 앞서 언급한 몇 개의 비율들에서 볼 수 있듯이 dice loss 단일보다 더 좋은 성능을 보여주는 경우도 존재한다.
사실 loss function은 모델의 결과를 좌우하는 수 많은 요소들 중 한 가지에 불과하다. 모델의 구조나, 데이터셋의 구성,
batch size나 전처리 및 증강 기법 등 무수히 많은 조건들이 학습에 영향을 미친다. 때문에 이론적인 부분에 너무 집중하여 다른 요소들에 대한 고려 사항을 놓치지 않도록 주의해야한다.
즉, 우리가 알아할 것은 이론적인 지식을 기반으로 방향성을 잡고 위와 같이 다양한 조건을 변경해가며 최고의 성능을 보일 수 있는 조건을 찾아야한다는 것이다.
이로써, VOC PASCAL dataset으로 semantic segmentation 해보는 프로젝트를 마무리 하겠다.
포스팅에 사용한 코드는 아래의 github에 업로드하였으니 참고하면 좋을 듯 하다.
포스팅에 대한 질문이나 잘못된 부분은 댓글 달아주시면 감사하겠습니다.
https://github.com/KDB0814/PASCAL_VOC
GitHub - KDB0814/PASCAL_VOC: PASCAL VOC 2012 Semantic segmentation example
PASCAL VOC 2012 Semantic segmentation example. Contribute to KDB0814/PASCAL_VOC development by creating an account on GitHub.
github.com
'Segmentation' 카테고리의 다른 글
| [VOC PASCAL 2012] Semantic segmentation 하기 - 3 (0) | 2024.03.03 |
|---|---|
| [VOC PASCAL 2012] Semantic segmentation 하기 - 2 (0) | 2024.03.02 |
| [VOC PASCAL 2012] Semantic segmentation 하기 - 1 (0) | 2024.02.27 |
| [ISBI 2012 segmentation] U-Net 모델 구현해보기-3 (0) | 2024.01.07 |
| [ISBI 2012 segmentation] U-Net 모델로 구현해보기-2 (0) | 2024.01.04 |

